
We are excited to introduce Mixtral, the latest innovation from Mistral AI. Mixtral implements an innovative approach to large language models, combining multiple expert models to deliver better performance and accuracy. In this blog post, we'll delve into what makes Mixtral unique, and more importantly, how you can seamlessly integrate it with the AIME API to build and deploy sophisticated and highly effective conversational AI solutions.
Mixtral, an ensemble of expert models, leverages the strengths of each specialized model to provide a comprehensive and robust AI system. This multifaceted approach ensures that Mixtral not only understands and processes natural language with exceptional precision but also adapts to a wide range of applications and industries. By integrating Mixtral with our AIME API, developers and businesses can easily unlock new potentials in their AI-driven interactions, from customer support to personalized user experiences.
MoE - Mixture of Experts
Mixtral represents a significant advancement in the realm of conversational AI, featuring a sparse mixture-of-experts network that revolutionizes model efficiency without sacrificing performance. Unlike traditional models, Mixtral operates as a decoder-only model, with a unique feedforward block that selects from a set of 8 distinct groups of parameters.
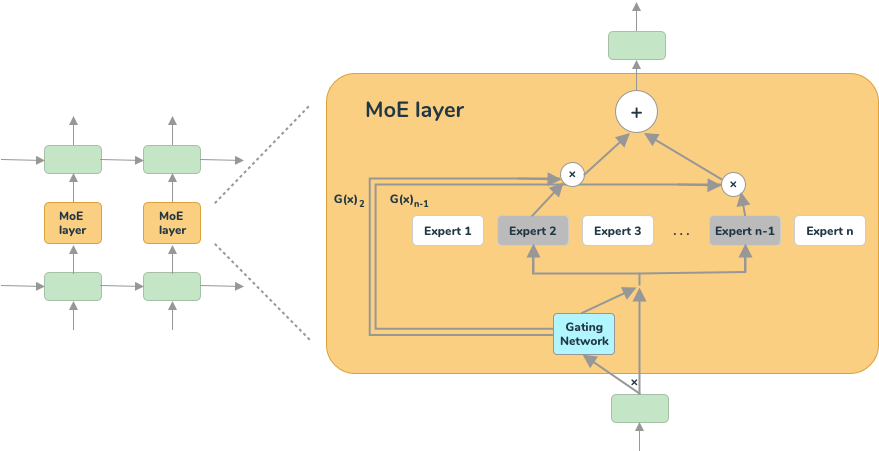
At every layer of Mixtral, for each token in the input, a specialized router network dynamically chooses two of these parameter groups, referred to as "experts," to process the token. These selected experts then combine their outputs additively, contributing to the final prediction.
This innovative approach allows Mixtral to increase the number of parameters in the model while effectively managing computational cost and latency. Despite its massive scale of 56B (8x7B) or even 176B (8x22B) parameters, Mixtral utilizes only a subset of all parameters per token. As a result, it processes input and generates output at a speed and cost equivalent to a much smaller model. More details of the hardware required to run the model can be found here.
Ready for Instructions: The Instruct Mechanism
The Mixtral models come in two flavours: the generic version and the instruct version. The instruct versions are fine tuned with the so called „Instruct“ training set, to turn the generic language model into a model that understands the so called „instruct syntax“.
The fine tuning of the model turns the generic language model, which initial purpose is to continue writing a text fragment, into a chat assistant that can be controlled with a „system prompt“ giving instructions: what is important, in which context and in which style or format the response should be given to stated questions or commands of the user.
The instructions can take various forms, such as explicit commands, user feedback, or contextual signals inferred from the conversation. In our Mixtral implementation, the instruct chat context will be decoded to the following format:
<s>
[INST]
<<SYS>>
System prompt
<</SYS>>
First user question
[/INST]
First assistant answer
</s>
<s>
[INST]
Second user question
[/INST]
Second assistant answer
</s>
<s>
[INST]
Third user question
[/INST]
Third assistant answer
</s>...Note: indentation is just for better readability, the actual decoded string does not contain indentations or line breaks
Each question-answer pair is enclosed by the begin-of-sentence token <s>and the end-of-sentence token </s>. The model is supposed to finish it's generated tokens with the end-of-sentence-token </s>.
Each user question has to be enclosed by the instruction tags [INST], [/INST].
Commands to the system like the initial system prompt have to be enclosed by the system tags <<SYS>>, <</SYS>>. The system command has to be within an user question, so enclosed by the instruction tags as well.
Example string in instruct format:
"<s> [INST] <<SYS>> System prompt <</SYS>> First user question [/INST] First assistant answer </s> <s> [INST] Second user question [/INST] Second assistant answer </s> <s> [INST] Third user question [/INST] Third assistant answer </s>..."Remembering every detail: Context length
Another key improvement of the Mixtral models is it's maximum context length of 32K for the 8x7B and 64K tokens for the 8x22B model, compared to only 8K context length of the competing Llama 3 models.
32K tokens correspond to approximately 24 thousand English words, which equals about 48 pages (DIN A4) with dense written text in letter size 11 points.
This longer context lengths allows much longer chats while remembering every statement of the chat, but comes with higher GPU memory demand. To utilize the full context length, the maximum batchsize has to be decreased depending on the used GPUs.
Exact numbers of the performance influence of the context length are described in the benchmark section of this article.
AIME Mixtral Implementation
Our Mixtral implementation is a fork of the original mixtral repository supporting all current Mixtral MoE model sizes: 8x7B and 8x22B and the Instruct fine tuned versions of the models.
Our Mixtral-Chat implementation by AIME provides the following features:
- improved sampling
- token-wise text output
- Interactive console chat
- Chat context in instruct format or plain text
- AIME API Server integration
- Batch-processing
With the integration in our AIME-API and its batch aggregation feature, it is possible to leverage the full possible inference performance of different GPU configurations by aggregating requests to be processed in parallel as batch jobs by the GPUs. This significantly increases the achievable throughput of chat requests.
Try out Mixtral Instruct Chat with the AIME API Demonstrator
The AIME-API-Server gives the option to run the Mixtral models as a JSON API endpoint to integrate the assistant capabilities into virtually any client device that has access to the Internet. To demonstrate the power of Mixtral with the AIME API Server, we run a fully working Mixtral Instruct Chat demonstrator using the AIME API Javascript client interface.
With the Mixtral demonstrator one can start a chat in various languages with example system prompts for different assistant scenarios to give a glimpse what would be possible with a tuned system prompt.
Getting Started: How to deploy Mixtral Chat on your hardware
In the following chapter we show how to setup, get the source, download the Mixtral models and run Mixtral as a console application or as a worker for serving HTTPS/HTTP requests.
Hardware Requirements of Mixtral 8x7B and 8x22B
Although the Mixtral models were trained on a cluster of H100 80GB GPUs, it is possible to run the models on different and smaller multi-GPU hardware for inference.
In table 1 we list a summary of the minimum GPU requirements and recommended AIME systems to run a specific Mixtral model with realtime reading performance:
| Model | Size | Minimum GPU Configuration | Recommended AIME Server | Recommended AIME Cloud Instance |
|---|---|---|---|---|
| 8x7B | 87GB | 4x NVIDIA RTX A6000 or RTX 6000 Ada 48GB | AIME G400 Workstation or AIME A4000 Server | C24-4XA6000-M6, C32-4X6000ADA-Y1 |
| 8x22B | 262GB | 4x NVIDIA A100/H100 80GB | AIME A4004 Server | C32-4XA180-Y1, C32-4XH100-Y1 |
A more detailed performance analysis of different hardware configurations can be found in the section Mixtral Inference GPU Benchmarks of this article.
Create an AIME ML Container
Here are instructions for setting up the environment using the AIME ML container management on your AIME server, cloud instance or workstation. Similar results can be achieved by using Conda or alike.
To create a PyTorch 2.3.0 environment for installation, we use the AIME ML container, as described in aime-ml-containers using the following command:
> mlc-create mixtral Pytorch 2.3.0 -w=/path/to/your/workspace -d=/destination/of/model/checkpointsThe -d parameter is only necessary if you don’t want to store the checkpoints in your workspace but in a specific data directory. It is mounting the folder /destination/of/model/checkpoints to /data inside the container.
Once the container is created, open it with:
> mlc-open mixtralYou are now working in the ML container being able to install all requirements and necessary pip and apt packages without interfering with the host system.
Clone the Mixtral-Chat Repository
Once inside the new Mixtral container clone the AIME Mixtral-Chat repository with:
[mixtral] user@client:/workspace$
> git clone https://github.com/aime-labs/mixtral_chatNow install the required pip packages in the container:
[mixtral] user@client:/workspace$
> pip install -r /workspace/mixtral_chat/requirements.txtDownload Mixtral Model Checkpoints
The model weights and tokenizer are free to download from the following sources:
| Model | Download Link |
|---|---|
| 8x7B Instruct | https://models.mistralcdn.com/mixtral-8x7b-v0-1/Mixtral-8x7B-v0.1-Instruct.tar |
| 8x22 Instruct | https://models.mistralcdn.com/mixtral-8x22b-v0-3/mixtral-8x22B-Instruct-v0.3.tar |
| 8x7B | Updated model coming soon! |
| 8x22B | https://models.mistralcdn.com/mixtral-8x22b-v0-3/mixtral-8x22B-v0.3.tar |
Run Mixtral as Interactive Chat in the Terminal
To try the Mixtral models as a chat bot in the terminal, use the following PyTorch script and specify the desired model size and the number of GPUs to use:
[mixtral] user@client:/workspace$
> torchrun --nproc_per_node <num_gpus> /workspace/mixtral_chat/chat.py --ckpt_dir /destination/of/model/checkpoints --tokenizer_path /destination/of/model/checkpoints/tokenizer.modelRun Mixtral Chat as Service with the AIME API Server
Setup AIME API Server
To read about how to setup and start the AIME API Server please see the setup section in the documentation.
Start Mixtral as API Worker
To connect the Mixtral-chat model with the AIME-API-Server ready to receive chat requests through the JSON HTTPS/HTTP interface, simply add the flag --api_server followed by the address of the AIME API Server to connect to:
[mixtral] user@client:/workspace$
> torchrun --nproc_per_node <num_gpus> /workspace/mixtral_chat/chat.py --ckpt_dir /destination/of/model/checkpoints --tokenizer_path /destination/of/model/tokenizer --api_server https://api.aime.info/The AIME API Server can be hosted on simple webservice webspace providers or on-premise within your company it-structure. In the example above, the model logs on as a worker for our AIME API demonstration server.
Now the Mixtral model acts as a worker instance for the AIME API Server ready to process jobs ordered by clients of the AIME API Server.
For a documentation on how to send client requests to the AIME API Server please read on here.
Mixtral Inference GPU Benchmarks
To measure the performance of your Mixtral worker connected to the AIME API Server, we developed a benchmark tool as part of our AIME API Server to simulate and stress the server with the desired amount of chat requests. First install the requirements with:
user@client:/workspace/aime-api-server/$
> pip install -r requirements_api_benchmark.txtThen the benchmark tool can be started with:
user@client:/workspace/aime-api-server/$
> python3 run_api_benchmark.py --api_server https://api.aime.info/ --total_requests <number_of_requests> --endpoint_name mixtral_chatrun_api_benchmark.py will send as many requests as possible in parallel and up to <number_of_requests> chat requests to the API server. Each request starts with either the initial context "Tell a long story: Once upon a time" or a long text utilizing the full maximum context length. Mixtral will generate a story until 500 tokens are generated. The processed tokens per second are measured and averaged over all processed requests.
Mixtral 8x7B Inference Performance
We show the throughput in generated tokens per second of the Mixtral 8x7B and 8x22B model for different GPU configurations. Since the maximum context length has a great impact on the maximum possible batch size, we measured with both 32K and 8K maximum context length.
Also the initial length of the prompt has an impact on the performance, since the input tensor needs to be processed in the model before generating new tokens can start. Therefore we compare the performance starting with an initial context utilizing the full context length and with a much shorter initial context.
In the bar charts the maximum possible batch size, which equals the parallel processable chat sessions is stated below the GPU model. The maximum possible batch size is directly related to the maximum context length and available GPU memory.
The results are shown as total possible throughput in tokens per second and the smaller bar shows the tokens per second for an individual chat session.
Mixtral 8x7B 32K Context length GPU Performance
With 32K context length the possible maximum batch sizes are relatively small, resulting in a non competitive total performance compared to models like Llama 3. Also the longer initial contexts reduce the performance significantly.
Reducing the maximum context length to 8K, the limit of Llama 3, leads to much higher batch sizes and thereby a more competitive total performance (see our Llama 3 article for Llama 3 benchmark results) :
Mixtral 8x7B 8K Context length GPU Performance
With 8K maximum context length its even possible to run 8x7B on only 2x6000 Ada.
Especially with 2x A100 and 2x H100 setups Mixtral 8x7B delivers better throughput in generated token/s than the Llama 3 70B model.
Mixtral 8x22B Inference Performance on 4x A100 80GB
The Mixtral 8x22B model has a much higher GPU memory demand, we currently only tested it on 4 x A100 80GB setup. Here are the results:
The human (silent) reading speed is about 5 to 8 words per second. With a ratio of 0.75 words per token, it is comparable to a required text generation speed of about 6 to 11 tokens per second to be experienced as not too slow.
A realtime usage of Mixtral 8x22B on a 4x A100 80GB is possible, but probably only feasible for applications that require highest text accuracy and only a moderate context length.
Conclusion
Integrating Mixtral with AIME API and its straightforward setup offers developers a scalable solution for deploying the Mixtral large language model to integrate it into software solutions. By utilizing Mixtral instruct mechanism alongside the AIME API Server, developers can easily create advanced applications like chatbots, virtual assistants or interactive customer support systems.
The hardware requirements for running Mixtral models are depending on the use case, especially on the desired maximum context length. For deployment various distributed GPU configurations and extendable setups are possible as infrastructure to serve thousands of requests. Even the minimum GPU requirements or smallest recommended AIME systems for each model size, with limitations for the Mixtral 8x22B model, ensure a more than real-time reading response performance for a seamless multi-user chat experience.




