
Stabe Diffusion is a deep learning based text-to-image AI model based on diffusion techniques which was first released in 2022. Since then, it has gone through several iterations (SD1, SD 1.5, SD 2.1, SD XL, SD XL Turbo, SD Turbo, SD 3) and improvements, like higher resolution images, text generation capabilities, faster processing, better sampling quality and text encoders.
Stable Diffusion 3 represents a significant evolution in AI-driven image generation, taking the groundwork laid by previous models like Stable Diffusion XL and enhancing it with advanced text encoding and improved image compression techniques. This results in faster, more memory-efficient outputs without sacrificing the quality that businesses rely on for high-end image generation.
In this article, you’ll learn how to run and deploy Stable Diffusion 3 (SD3) both on local hardware and as a scalable web service. We'll also benchmark SD3 on various GPUs, offering insight into how to choose the optimal setup for your GenAI image generation needs.
Architecture of Stable Diffusion 3
Stable Diffusion 3 incorporates a new Multimodal Diffusion Transformer (MMDiT) architecture which builds upon the foundation of the Diffusion Transformer (DiT) but takes it a step further. By allowing bidirectional flow of information between image and text tokens, SD3 achieves superior comprehension and typography in its outputs. This is particularly evident in the model's improved prompt following and flexibility in creating images that focus on various subjects and qualities while maintaining high stylistic adaptability.
Another key component of SD3's architecture is its use of multiple text embedders — two CLIP models and a T5 model to encode text representations, alongside an improved autoencoding model for image tokens. This approach contributes to the model's enhanced text understanding and spelling capabilities, setting it apart from previous versions of Stable Diffusion.
The architecture of Stable Diffusion 3 also employs a Rectified Flow (RF) formulation, which connects data and noise on a linear trajectory during training. This results in straighter inference paths, allowing for sampling with fewer steps. The SD3 team has further refined this approach by introducing a novel trajectory sampling schedule that gives more weight to the middle parts of the trajectory. This innovation has led to consistent performance improvements across various sampling regimes.
The scalability of the SD3 architecture is another notable feature. The model suite ranges from 800 million to 8 billion parameters, offering flexibility for different hardware configurations and use cases. This scalability, combined with the architecture's efficiency, allows SD3 to fit into consumer-grade hardware while still delivering state-of-the-art performance.
SD3 vs. Previous Models
Stable Diffusion is a text-to-image model that has evolved rapidly since its first release in August 2022, making high-quality image generation accessible on consumer-grade GPUs. Early versions (v1.0 to v1.2) focused on improving image quality and prompt interpretation, supporting resolutions up to 512×512 pixels.
Versions 1.4 and 1.5 enhanced detail and prompt accuracy, with v1.5 becoming widely popular for its ability to generate realistic and complex images. In November 2022, Stable Diffusion 2.0 introduced higher resolution (768×768 pixels) and inpainting capabilities which lets you modify subsections of an image. The most important shift was replacing the text encoder to the new OpenCLIP text encoder for better prompt understanding.
Stable Diffusion XL (SDXL), released in July 2023, featured a native resolution of 1024×1024 pixels and employs a unique dual text encoder system, combining OpenCLIP ViT-bigG and CLIP ViT-L for enhanced prompt understanding. SDXL's architecture consists of a two-stage diffusion process with a base model (3.5B parameters) and a refiner model (3.1B parameters), totaling approximately 6.6 billion parameters. This larger model size resulted in improved image quality and coherence, especially for complex scenes, albeit with a slight increase in inference time compared to its predecessors.
Stable Diffusion 3, announced in March 2024, represents a significant leap by offering enhanced text rendering capabilities, allowing for more accurate and legible text generation within images — a feature that was challenging for previous versions. SD3 supports 2048×2048 pixels and has an improved cross-attention mechanism for better text-image alignment.
How to Improve Prompting in SD3 for More Precise Results
Optimizing your prompts in Stable Diffusion 3 is key to achieving high-quality, tailored images. By leveraging features like negative prompts, adjusting sampling steps, and fine-tuning the Classifier-Free Guidance (CFG) scale, you can gain greater control over the output.
Negative Prompt
The negative prompt allows you to specify what you don’t want in your generated images. By providing examples or descriptions of undesirable elements, you can guide the model to avoid specific features or characteristics. This helps you achieve more refined and tailored outputs by eliminating unwanted artifacts, styles, or subjects that don’t align with your vision. For example, here is a comparison of the same prompt with and without a negative prompt:
Prompt: Create a hyper-realistic image of a layered chocolate cake with rich chocolate frosting and ganache drips, displayed on a beautifully set table.


Left: Without negative prompt | Right: With negative prompt "Avoid any strawberries, fruits, or decorations that are not chocolate-themed"
As you see in the images above, without a negative prompt, the model included elements like fruits or non-chocolate toppings. By specifying a negative prompt, such as "Avoid any strawberries, fruits, or decorations that are not chocolate-themed," you guide the model to focus solely on chocolate elements, ensuring the final image aligns closely with your vision.
Sampling Steps
Sampling steps refer to the number of iterations Stable Diffusion 3 undergoes to generate an image. Each step progressively refines the output by adjusting the pixel values based on the model’s learned patterns. More sampling steps generally lead to higher-quality images, as the model has more opportunities to fine-tune the details. However, keep in mind that increasing the number of steps also raises the computational cost and time required for image generation, so you’ll want to find a balance based on your specific needs.
Prompt: An alien desert landscape with two suns, towering alien formations with strange creatures in the sky. No Spaceships



Left: Sampling Steps 10 | Center: Sampling Steps 60 | Right: Sampling Steps 28
Testing the same prompt with using 10 sampling steps produced a quicker output but lacked detail and refinement, while 60 steps resulted in highly detailed images with strange creatures in the sky. However, using the standard 28 sampling steps provided the most balanced output, with correctly depicting two suns, whereas the other images only featured one sun.
Classifier-Free Guidance Scale (CFG)
The Classifier-Free Guidance Scale (CFG) in Stable Diffusion 3 influences how closely the generated images adhere to your prompts. This parameter adjusts the balance between your prompt (what you want to generate) and the guidance towards specific traits or styles. A higher CFG scale will lead to outputs that closely match your provided prompt, while a lower scale may introduce more randomness and creativity, allowing for broader interpretations. This control is crucial for achieving the desired level of specificity or creativity in your generated images.
Prompt: An alien desert landscape with two suns, towering alien formations with strange creatures in the sky. No Spaceships



Left: CFG Scale 10.0 | Center: CFG Scale 7.5 | Right: CFG Scale 4.0
These components work together in Stable Diffusion 3 to give you greater control over the image generation process, enabling you to customize and refine outputs based on your preferences and project requirements.
Getting Started: How to run SD3 on your local workstation and as scalable web service
Required hardware
| Model Size | Minimum GPU Configuration | Recommended AIME Server | Recommended AIME Cloud Instance |
|---|---|---|---|
| SD3 Medium | NVIDIA RTX A5000 or RTX 5000 Ada | AIME G500 Workstation or AIME A4000 Server | V10-1XA5000-M6 or V14-1XA100-M6 |
New Features Added by AIME
AIME has added several new features to the original repository which is available at Stable Diffusion 3 Micro-Reference Implementation.
One key addition is the ability to generate multiple images in a single call. This streamlines the creative process by allowing users to request multiple variations of an image simultaneously, rather than generating them one by one. This significantly reduces time and effort required from your end when working with various designs or concepts.
Another notable feature is the option to preview images during processing. You can see live previews as the images are being generated, enabling immediate feedback and quick adjustments to parameters if the results are not as expected. This will make the process more interactive and responsive to creative needs.
AIME has also expanded the system’s core capabilities to include image-to-image function which allows users to upload an existing image and modify it using a text prompt, offering powerful tools for creative transformation, style transfer, and enhancements.
The system is further strengthened by integration of the AIME API server, enabling scalable web API service deployment. This supports access by multiple users and applications, making it ideal for cloud environments and large scale operations.
Step-by-step guide to set up Stable Diffusion 3 using AIME MLC
Step 1: Download the Model Weights
Begin by downloading the pre-trained SD3 Medium model weights from Hugging Face:
sudo apt-get install git-lfs
git lfs install
mkdir /destination/to/checkpoints
cd /destination/to/checkpoints
git clone https://huggingface.co/stabilityai/stable-diffusion-3-mediumStep 2: Clone the Client Repository
Next, clone the AIME's reference implementation repository:
cd /destination/to/repo
git clone https://github.com/aime-labs/stable_diffusion_3Step 3: Set Up AIME MLC
Use AIME's MLC tool to containerize your SD3 environment and automate dependencies installation:
mlc-create sd3 Pytorch 2.3.1-aime -d="/destination/to/checkpoints" -w="/destination/to/repo"The -d flag will mount /destination/to/checkpoints to /data in the container.
The -w flag will mount /destination/to/repo to /workspace in the container.
Step 4: Install Dependencies
After entering the SD3 environment, install the required dependencies:
mlc-open sd3
pip install -r /workspace/stable_diffusion_3/requirements.txtRunning Stable Diffusion 3 as API and Web Service
To run SD3 as an API and web service, you'll follow a two-step process:
- Setting up the AIME API server and then
- Starting the SD3 worker to process image generation requests.
Here's a breakdown of how to set it up and run SD3 effectively.
1. Set up the Environment
Before starting, it’s recommended to create a virtual environment to isolate dependencies. Follow these steps:
Create and activate a virtual environment:
python3 -m venv venv
source ./venv/bin/activateClone the AIME API Server repository:
git clone https://github.com/aime-team/aime-api-server.git
cd aime-api-serverpip install -r requirements.txtOptional: Install ffmpeg (required for image and audio conversion):
sudo apt install ffmpeg2. Start the API Server
Once the environment is set up and dependencies are installed, you can start the AIME API Server. Use the following command:
python3 run_api_server.py [-H HOST] [-p PORT] [-c EP_CONFIG] [-wp WORKER_PROCESSES] [--dev]This command starts the server and accepts optional parameters:
- -H, --host: The host address for the server (default: 0.0.0.0).
- -p, --port: The port on which the server will run (default: 7777).
- -c, --ep_config: Specify the endpoint configuration file/folder (default: ./endpoints).
- -wp, --worker_processes: Number of worker processes for handling API requests (default: 1).
- --dev: If you want to run the server in development mode for debugging.
3. Start Stable Diffusion 3 as an API Worker
After setting up the API server, you can start Stable Diffusion 3 as a worker, which will handle image generation requests sent to the server.
Run the following command to start SD3 as an API worker:
mlc-open sd3
python3 /workspace/stable_diffusion_3/main.py --api_server <url to API server> --ckpt_dir /data/stable-diffusion-3-medium- --api_server: This is the URL of the AIME API Server where the SD3 worker will be connected. Replace
with the actual URL - --ckpt_dir: The directory where the Stable Diffusion 3 model weights (checkpoints) are stored. Update this path to point to the folder where your model is located, for example, /data/stable-diffusion-3-medium.
Once executed, the SD3 worker will be ready to process requests for image generation through the AIME API server.
Here is how the SD3 demo endpoint that comes with AIME API Server as an example looks like:
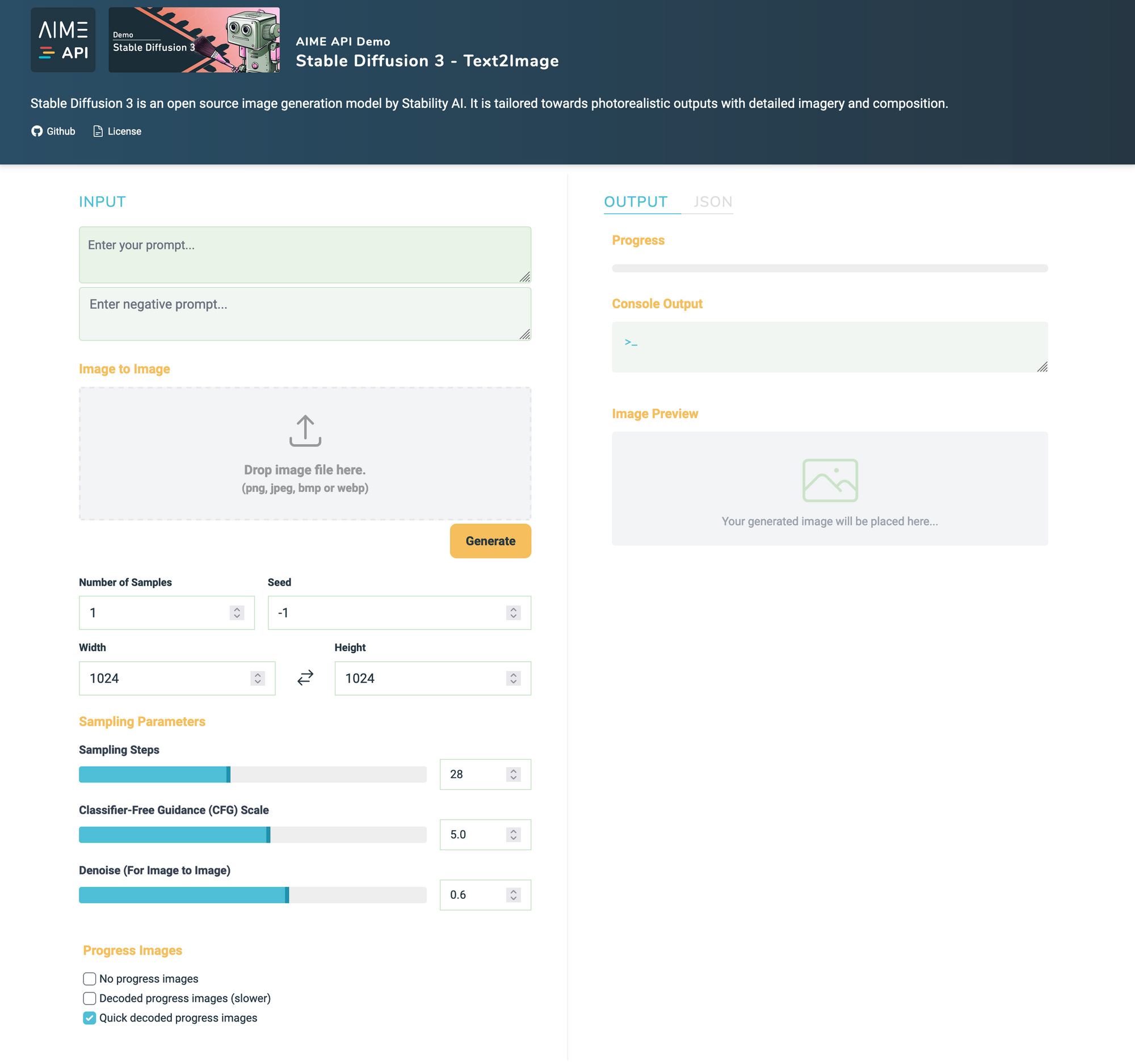
Benchmarking SD3: GPU Performance Metrics
We've previously explored running Stable Diffusion with an AIME Workstation using AIME MLC, and now with the release of Stable Diffusion 3, the capabilities have only expanded further. The performance of Stable Diffusion 3 largely depends on the GPU model used. We ran benchmarks to determine how many images per second SD3 can generate across different GPUs:
The chart presents a benchmark comparison of various GPU models running AIME Stable Diffusion 3 Inference using Pytorch 2.3.1. The benchmark measures the number of images that can be generated per second, providing insights into the performance capabilities of different GPUs for this specific task.
GPU Models Tested:
- H100 80GB
- A100 80GB
- RTX 6000 Ada 48GB
- RTX 5000 Ada 32GB
- RTX A5000 24GB
Performance Metric:
The benchmark uses "Generated Images per Second" as the primary performance indicator.
Batch Size Comparison:
Each GPU was tested with two batch sizes:
- Batch size 1
- Batch size 16
Influence of Batch Size on Performance
Our recent benchmark of AIME SD3 using PyTorch 2.3.1 demonstrated that high-end GPUs like the H100 80 GB and A100 80 GB showed top performance, generating approximately 0.22 images per second. However, the performance gap between these models and the RTX 6000 Ada and 5000 Ada GPUs was less significant than anticipated.
Notably, the impact of increasing batch sizes was more significant on the RTX 6000 and 5000 Ada GPUs compared to the A100. However, the overall scaling of SD3 with larger batch sizes appears limited across all GPU models. The H100 did not stand out significantly either. Further analysis highlights that for the RTX 6000 Ada GPU, performance improvements plateau beyond a batch size of 8.
These benchmark results provide valuable insights for optimizing SD3 deployments, emphasizing the importance of careful hardware selection and configuration optimization. Simply choosing the most powerful GPU may not always lead to proportional performance gains, revealing a complex relationship between GPU specifications, batch sizes, and actual performance in real-world scenarios.
Recommendations for GPU Solutions
Best Performance
For maximum performance, the H100 80GB or A100 80GB are the top choices. These are ideal for production environments where speed is critical and budget is less of a concern.
Affordable High-Performance
The RTX 6000 Ada 48GB or RTX 5000 Ada 32GB offer excellent performance at potentially lower costs.These GPUs provide a good balance of speed and affordability, making them suitable for many professional applications.
Budget-Friendly Option
The RTX A5000 24GB, while less powerful, could be a good entry point for those with limited budgets or lower performance requirements. It's suitable for smaller projects or development environments where top-tier speed isn't necessary.
AIME Stable Diffusion 3 API Demo Service
We’re excited to announce the launch of our Stable Diffusion 3 Demo API Service. This public demo will allow you to experience the full capabilities of the Stable Diffusion 3 system, including all the new features and enhancements introduced by AIME.
Whether you're a developer looking to integrate state-of-the-art generative AI into your applications or a creative professional seeking a more efficient way to explore multiple design variations, our API service will offer a robust solution. The demo will showcase:
- Multiple Image Generation in a single call, speeding up workflows.
- Real-time Image Previews, enabling instant feedback and rapid parameter adjustments.
- Image-to-Image Transformation, unlocking new possibilities for creative enhancements and style transfers.
Conclusion
In this article we explained how to run and deploy Stable Diffusion 3 on local hardware and as a scalable web service.
We invite you to explore our Stable Diffusion 3 Demo Endpoint of our AIME API and see how it can revolutionize your creative or development process. The service will be available to the public with the release of this blog, and you can access it here.
Stay tuned for our next deep dive into FLUX Image Generation, a cutting-edge AI technology pushing the boundaries of creative visuals.




