
Updating or modifying a GPU deep learning environment can feel like a precarious game of Jenga—one small change often leads to the collapse of the entire stack. This creates a scenario where the phrase “never change a running system” might seem like the safer choice, rather than risking an update that could render the system unusable for hours or even days.
The challenge becomes even more daunting when multiple users share the system or when different frameworks must coexist. For instance, TensorFlow 2.16.1 requires CUDA 12.3, while PyTorch 2.5.0 supports CUDA 12.1 or CUDA 11.8—leading to a confusing and frustrating compatibility tangle.
A functional GPU deep learning setup hinges on precise compatibility between several components, including:
- The operating system (OS) version
- NVIDIA driver version
- CUDA version
- CuDNN version
- Additional CUDA libraries and their versions
- Python version
- Python packages and their associated system libraries
Several approaches aim to simplify this complex process and mitigate these compatibility issues:
Conda
An advanced version of Python's venv, Conda simplifies setting up virtual environments for Python packages while also accounting for required system libraries (e.g., apt packages). Conda provides versions of deep learning frameworks tailored to specific CUDA versions to a certain extent.
pros
- more powerful then Python venv
- nice for switching among different Python package setups for different projects which rely on compatible deep learning framework versions
- well supported by PyTorch
cons
- limited support from some major deep learning frameworks
- ineffective when different system libraries or driver versions are required
Virtual Machines
The all-round solution for multi user and multi version abstraction problems. Setup a virtual machine for each user, deep learning framework or project.
pros
- safest option to separate different users and framework setups
- dedicated resource management possible
cons
- only available for GPUs that have virtual machine driver support (Tesla, Quadro)
- very resource intensive
- expensive to maintain
- unflexibel in separating environment and project data
Docker
Containers, like those provided by Docker, represent the next generation of virtualization. Unlike full virtual machines, Docker virtualizes only what’s necessary. Containers package all required resources and can run completely different version stacks from the host system. Interfaces also allow containers to interact directly with the host system.
pros
- more lightweight than virtual machines
- Docker container available for most deep learning frameworks
- compatible with all NVIDIA GPUs
- delivers bare-metal performance
- highly flexible in configuration and use
cons
- steep learning curve; limited conventions for "correct" usage
- can become disorganized and confusing without proper management
- lacks built-in multi-user features
AIME MLC machine learning container management system
We’ve designed the AIME MLC to streamline the complexities of GPU deep learning environments, offering an intuitive and efficient way to manage setups across users, frameworks, and hardware configurations.
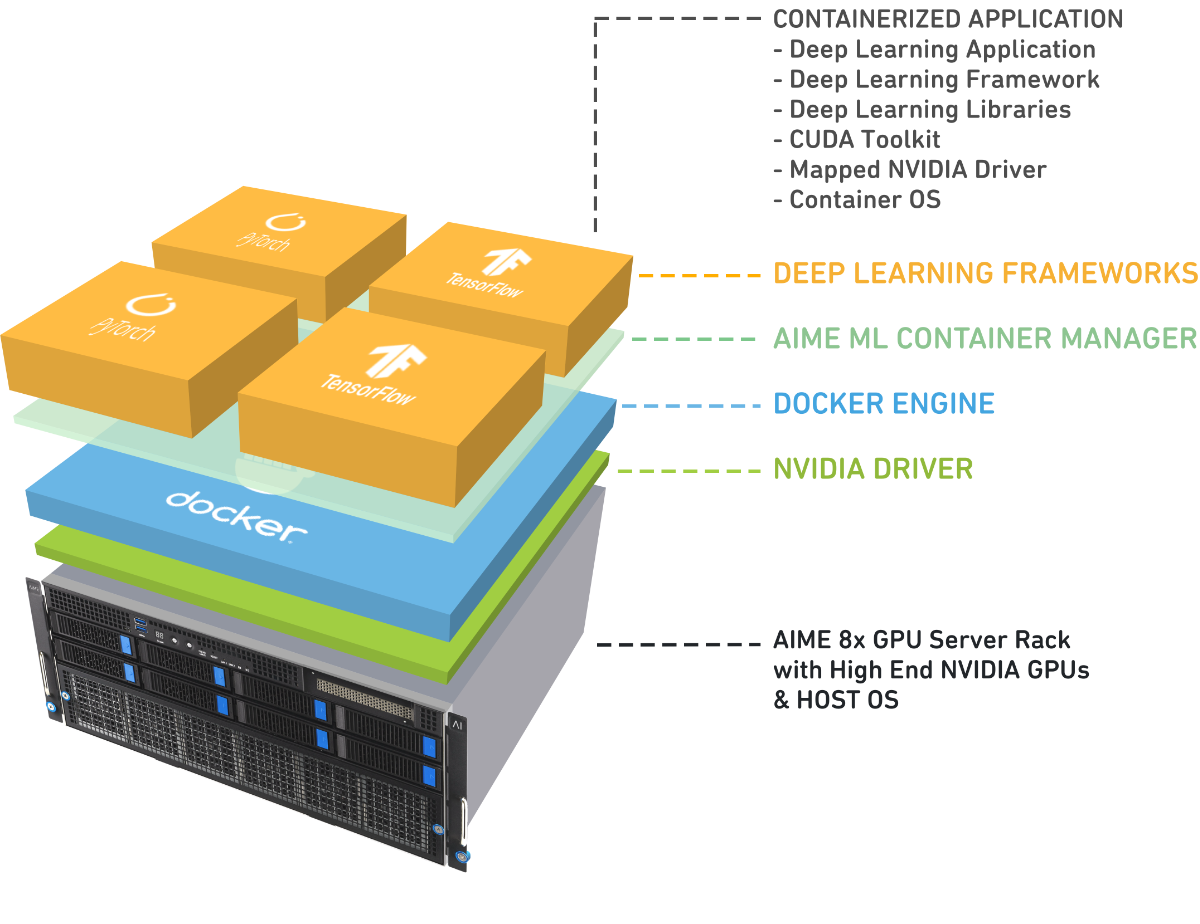
Features
- Effortless framework setup: launch a specific version of PyTorch or TensorFlow with a single command
- Parallel framework support: run multiple versions of machine learning frameworks and their required libraries simultaneously
- Library management made simple: handle all dependencies (CUDA, cuDNN, cuBLAS, etc.) within containers, ensuring the host system remains unaffected
- Clean Separation for Easy Testing: keep user code and framework installations fully isolated, enabling seamless testing of your code on different framework versions in just minutes
- Multi-session support: open and run multiple shell sessions within the same container simultaneously
- Multi-user functionality: ensure container environments are securely separated for each user
- Multi-GPU allocation: assign GPUs flexibly to specific users, containers, or sessions as needed
- Bare-metal Performance: enjoy the same performance as a direct installation on hardware
- Comprehensive repository: access a vast library of pre-configured containers for all major deep learning framework versions
So how does it work?
Explore the essential commands that guide you through every step—creating, opening, starting, stopping, and deleting your own machine learning containers with ease.
To view detailed information about all available commands, use:
> mlc -hTo get help for a specific command (e.g., create), use:
> mlc create -hCreate a machine learning container
mlc create container_name framework version [-w workspace_dir] [-d data_dir] [-m models_dir] [-s|--script] [-arch|--architecture gpu_architecture] [-g|--num_gpus all]
To create a new container following options are available.
Available frameworks:
Pytorch, Tensorflow
The following architectures are currently available:
CUDA_ADA, CUDA_AMPERE, CUDA for NVIDIA GPUs and ROCM6 and ROCM5 for AMD GPUs.
Available versions for CUDA_ADA, which corresponds to NVIDIA Ada Lovelace based GPUs (RTX 4080/4090, RTX 4500/5000/6000 Ada, L40, L40S):
Pytorch: 2.5.0, 2.4.0, 2.3.1-aime, 2.3.0, 2.2.2, 2.2.0, 2.1.2-aime, 2.1.1-aime, 2.1.0-aime, 2.1.0, 2.0.1-aime, 2.0.1, 2.0.0, 1.14.0a-nvidia, 1.13.1-aime, 1.13.0a-nvidia, 1.12.1-aime
Tensorflow: 2.16.1, 2.15.0, 2.14.0, 2.13.1-aime, 2.13.0, 2.12.0, 2.11.0-nvidia, 2.11.0-aime, 2.10.1-nvidia, 2.10.0-nvidia, 2.9.1-nvidia
To print the current available GPU architectures, frameworks and corresponding versions, use:
> mlc create --infoExample to create a container in script mode using Pytorch 2.4.0 with the name 'my-container' and with mounted user home directory as workspace, /data and /models as data and models directory, use:
> mlc create my-container Pytorch 2.4.0 -w /home/user_name/workspace -d /data -m /models
Open a machine learning container
mlc open container_name
To open the created machine learning container "my-container"
> mlc open my-container
Will output:
[my-container] starting container
[my-container] opening shell to container
________ _______________
___ __/__________________________________ ____/__ /________ __
__ / _ _ \_ __ \_ ___/ __ \_ ___/_ /_ __ /_ __ \_ | /| / /
_ / / __/ / / /(__ )/ /_/ / / _ __/ _ / / /_/ /_ |/ |/ /
/_/ \___//_/ /_//____/ \____//_/ /_/ /_/ \____/____/|__/
You are running this container as user with ID 1000 and group 1000,
which should map to the ID and group for your user on the Docker host. Great!
[my-container] admin@aime01:/workspace$
The container is run with the access rights of the user. To use privileged rights like for installing packages with 'apt' within the container use 'sudo'. The default is that no password is needed for sudo, to change this behaviour set a password with 'passwd'.
Multiple instances of a container can be opened with mlc open. Each instance runs in its own process.
To exit an opened shell to the container type 'exit' on the command line. The last exited shell will automatically stop the container.
List available machine learning containers
mlc list
will list all available containers for the current user
> mlc list
will output for example:
Available ml-containers are:
CONTAINER FRAMEWORK STATUS
[torch-vid2vid] Pytorch-1.2.0 Up 2 days
[tf1.15.0] Tensorflow-1.15.0 Up 8 minutes
[mx-container] Mxnet-1.5.0 Exited (137) 1 day ago
[tf1-nvidia] Tensorflow-1.14.0_nvidia Exited (137) 1 week ago
[tf1.13.2] Tensorflow-1.13.2 Exited (137) 2 weeks ago
[torch1.3] Pytorch-1.3.0 Exited (137) 3 weeks ago
[tf2-gpt2] Tensorflow-2.0.0 Exited (137) 7 hours ago
List active machine learning containers
mlc stats
show all current running ml containers and their CPU and memory usage
> mlc-stats
Running ml-containers are:
CONTAINER CPU % MEM USAGE / LIMIT
[torch-vid2vid] 4.93% 8.516GiB / 63.36GiB
[tf1.15.0] 7.26% 9.242GiB / 63.36GiB
Start machine learning containers
mlc start container_name
to explicitly start a container
'mlc start' is a way to start the container to run installed background processes, like an installed web server, on the container without the need to open an interactive shell to it.
For opening a shell to the container just use 'mlc-open', which will automatically start the container if the container is not already running.
Stop machine learning containers
ml stop container_name [-f]
to explicitly stop a container.
'mlc stop' on a container is comparable to a shutdown of a computer, all activate processes and open shells to the container will be terminated.
To force a stop on a container use:
mlc stop my-container -f
Remove/Delete a machine learning container
mlc remove container_name
to remove the container.
Warning: the container will be unrecoverable deleted only data stored in the /workspace and /data and /models directory will be kept. Only use to clean up containers which are not needed any more.
mlc remove my-container
Update MLC
mlc update-sys
to update the container management system to the latest version.
The container system and container repo will be updated to latest version. Run this command to check if new framework versions are available. On most systems privileged access (sudo password) is required to do so.
mlc update-sys
That's it
With these fundamental yet powerful commands, you can effortlessly create, open, and manage your deep learning containers.
Inside the container, you can install both apt and Python packages without affecting the host system. While it's possible to use an additional venv to manage Python packages, it’s often unnecessary —simply create a new container to experiment with different setups.
Run multiple instances of your containers and seamlessly manage your deep learning sessions. Share data and source files between the container and host system through the mounted workspace directory.
f you're working on a workstation, you can edit and manage your data and code using your favorite desktop editor—such as Visual Studio Code—directly on the host system. Test your changes immediately—no need for tedious pushing and pulling of files, using a remote desktop connection.
Installation
AIME machines come pre-installed with AIME Machine Learning Container Management system. Simply log in, and the commands described above will be ready to use.
AIME ML containers is also available as a open source project on GitHub.




