
Wir freuen uns, Mixtral vorzustellen, die neueste Innovation von Mistral AI. Mixtral implementiert einen innovativen Ansatz für große Sprachmodelle, indem es mehrere Expertenmodelle kombiniert, um eine bessere Leistung und Genauigkeit der Ausgabe zu erzielen. In diesem Blogbeitrag wird erläutert, was Mixtral einzigartig macht und wie es mittels der AIME API in Anwendungen integriert werden kann, um anspruchsvolle und hochwirksame Konversations-KI-Lösungen zu entwickeln und bereitzustellen.
Mixtral besteht aus einem Ensemble von Expertenmodellen und nutzt die Stärken jedes dieser spezialisierten Modelle, um ein umfassendes und robustes KI-System bereitzustellen. Dieser Ansatz stellt sicher, dass Mixtral nicht nur natürliche Sprache mit außergewöhnlicher Präzision versteht und verarbeitet, sondern sich auch an eine breite Palette von Anwendungen und Branchen anzupassen vermag. Die Integration von Mixtral in die AIME API bietet Entwicklern und Unternehmen die Möglichkeit, KI-gesteuerte Interaktionen in ihre Prozesse und Anwendungen zu integrieren, von der Kundenbetreuung bis hin zu personalisierten Benutzererlebnissen.
MoE - Mixture of Experts
Mixtral stellt einen bedeutenden Fortschritt im Bereich der konversationellen KI dar und bietet ein "Sparse Mixture-of-Experts" - direkt übersetzt so etwas wie ein sparsames Netzwerk einer Mischung von Experten, das die Effizienz des Modells optimiert, ohne seine Leistung zu beeinträchtigen. Im Gegensatz zu herkömmlichen LLM-Modellen funktioniert Mixtral als reines Decoder-Modell mit einem speziellen Feedforward-Block, der aus einer Menge von 8 verschiedenen Parametergruppen auswählt.
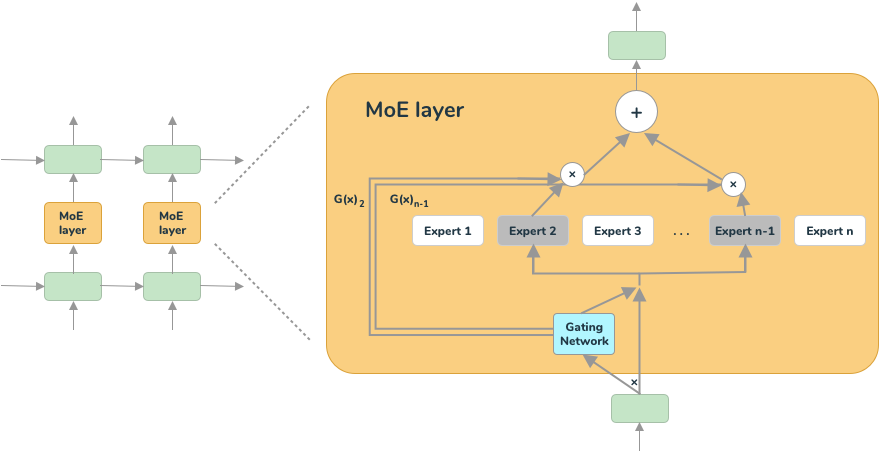
In jeder Schicht von Mixtral wählt ein spezialisiertes Router-Netzwerk dynamisch zwei dieser Parametergruppen, die als „Experten“ bezeichnet werden, um das jeweilige Token zu verarbeiten. Diese ausgewählten Experten kombinieren dann ihre Ausgaben additiv und tragen so zur endgültigen Vorhersage bei.
Dieser innovative Ansatz ermöglicht es Mixtral, die Anzahl der Parameter im Modell zu erhöhen, was die Rechenzeit und die Ausgabe-Latenz effektiv verringert. Trotz seiner enormen Größe von 56 Milliarden (8x7B) oder sogar 176 Milliarden (8x22B) Parametern nutzt Mixtral pro Token nur einen Teil aller Parameter. Dadurch verarbeitet es Eingaben und generiert Ausgaben mit einer Geschwindigkeit bzw. Rechenzeit, die einem viel kleineren Modell entsprechen. Weitere Details zur Hardware, die zum Ausführen des Modells erforderlich ist, findet sich hier.
Bereit für Anweisungen: Der Instruct-Mechanismus
Die Mixtral-Modelle gibt es in zwei Varianten: die generische und die Instruct-Variante. Die Instruct-Versionen wurden mit dem sogenannten „Instruct“-Datensatz trainiert (Fine Tuning), um das generische Sprachmodell in ein Modell zu verwandeln, das die sogenannte „Instruct-Syntax“ versteht.
Das Fine-Tuning des Modells überführt das generische Sprachmodell, dessen ursprünglicher Zweck es ist, ein Textfragment fortzusetzen, in einen Chat-Assistenten, der mit einer „System-Prompt“-Anweisung gesteuert werden kann, um zu markieren, in welchem Kontext und in welchem Stil oder Format die Antwort auf die gestellten Fragen oder Befehle des Benutzers gegeben werden soll.
Die Anweisungen können verschiedene Formen annehmen, wie explizite Befehle, Benutzerfeedback oder kontextuelle Signale, die aus dem Gesprächsverlauf abgeleitet werden. In unserer Mixtral-Implementierung wird der Instruct-Chat-Kontext in folgendem Format dekodiert:
<s>
[INST]
<<SYS>>
System-Prompt
<</SYS>>
Erste Benutzerfrage
[/INST]
Erste Assistentenantwort
</s>
<s>
[INST]
Zweite Benutzerfrage
[/INST]
Zweite Assistentenantwort
</s>
<s>
[INST]
Dritte Benutzerfrage
[/INST]
Dritte Assistentenantwort
</s>...Hinweis: Die Einrückung dient nur der besseren Lesbarkeit, die tatsächliche dekodierte Zeichenkette enthält keine Einrückungen oder Zeilenumbrüche.
Jedes Frage-Antwort-Paar ist durch das Anfangs- und Endsatz-Token <s>, </s> eingeschlossen. Das Modell soll seine generierten Token mit dem Endsatz-Token </s> abschließen.
Jede Benutzerfrage muss von den Anweisungs-Tags [INST], [/INST] umschlossen sein.
Befehle an das System wie der anfängliche System-Prompt, müssen von den System-Tags <<SYS>>, <</SYS>> umschlossen sein. Der Systembefehl muss ebenfalls innerhalb einer Benutzerfrage liegen, also von den Anweisungs-Tags umschlossen sein.
Beispielzeichenkette im Instruct-Format:
"<s> [INST] <<SYS>> System-Prompt <</SYS>> Erste Benutzerfrage [/INST] Erste Assistentenantwort </s> <s> [INST] Zweite Benutzerfrage [/INST] Zweite Assistentenantwort </s> <s> [INST] Dritte Benutzerfrage [/INST] Dritte Assistentenantwort </s>..."Jedes Detail erinnern: Kontextlänge
Eine weitere wichtige Verbesserung der Mixtral-Modelle ist die maximale Kontextlänge von 32K für das 8x7B und 64K Token für das 8x22B Modell im Vergleich zu nur 8K Kontextlänge der konkurrierenden Llama 3 Modelle.
32K Token entsprechen etwa 24.000 englischen Wörtern, was etwa 48 Seiten (DIN A4) mit dicht geschriebenem Text in Schriftgröße 11 Punkten entspricht.
Diese längeren Kontextlängen ermöglichen viel längere Chats, in denen jede Aussage des Gesprächs vom Modell erinnert wird. Dies erfordert jedoch einen größeren GPU-Speicher. Um die volle Kontextlänge zu nutzen, muss die maximale Batch-Größe je nach verwendeten GPUs reduziert werden.
Genauere Zahlen zum Einfluss der Kontextlänge auf die Leistung finden sich im Benchmark-Abschnitt dieses Artikels.
AIME Mixtral Implementierung
Unsere Mixtral-Implementierung ist ein Fork des ursprünglichen Mixtral-Repositories, der alle aktuellen Mixtral MoE-Modellgrößen unterstützt: 8x7B und 8x22B sowie die Instruct-Feinabgestimmten Versionen der Modelle.
Unsere Mixtral-Chat-Implementierung von AIME bietet die folgenden Funktionen:
- Verbessertes Sampling
- Tokenweise Textausgabe
- Interaktiver Konsolen-Chat
- Chat-Kontext im Instruct-Format oder als Klartext
- AIME API-Server-Integration
- Batch-Verarbeitung
Mit der Integration in unsere AIME-API und der Batch-Aggregationsfunktion ist es möglich, die gesamte mögliche Inferenzleistung verschiedener GPU-Konfigurationen auszuschöpfen, indem Anfragen aggregiert und parallel als Batch-Jobs von den GPUs verarbeitet werden. Dies erhöht die erreichbare Durchsatzrate von Chat-Anfragen erheblich.
Mixtral Instruct Chat mit dem AIME API Demonstrator ausprobieren
Der AIME-API-Server bietet die Möglichkeit, die Mixtral-Modelle als JSON-API-Endpunkt zu betreiben, um sie in praktisch jedem mit dem Internet verbundenen Client-Gerät nutzen zu können. Um die Leistungsfähigkeit von Mixtral mit dem AIME API Server zu demonstrieren, betreiben wir einen voll funktionsfähigen Mixtral Instruct Chat-Demonstrator, der die AIME API Javascript-Client-Schnittstelle verwendet.
Mit dem Mixtral-Demonstrator kann man in verschiedenen Sprachen chatten. Um einen Einblick zu geben, was mit einem entsprechend abgestimmten System-Prompt möglich ist, sind für verschiedene Nutzungsszenarien Beispiel-System-Prompts auswählbar.
Erste Schritte: Wie man Mixtral Chat mit eigener Hardware einsetzt
Im folgenden Absatz zeigen wir, wie man sein System einrichtet, um Mixtral zu betreiben, indem man den Quellcode klont, die Mixtral-Modelle herunterlädt und sie als Konsolenanwendung oder als API-Worker zum Empfangen von HTTPS/HTTP-Anfragen ausführt.
Hardwareanforderungen für Mixtral 8x7B und 8x22B
Obwohl die Mixtral-Modelle auf einem Cluster von H100 80GB GPUs trainiert wurden, ist es möglich, die Modelle auf günstigerer Multi-GPU-Hardware zu betreiben.
In Tabelle 1 findet sich eine Zusammenfassung der minimalen GPU-Anforderungen und empfohlenen AIME-Systeme zum Ausführen eines spezifischen Mixtral-Modells mit Echtzeit-Leseleistung:
| Modell | Größe | Minimale GPU-Konfiguration | Empfohlener AIME Server | Empfohlene AIME Cloud Instanz |
|---|---|---|---|---|
| 8x7B | 87GB | 4x NVIDIA RTX A6000 oder RTX 6000 Ada 48GB | AIME G400 Workstation oder AIME A4000 Server | C24-4XA6000-M6, C32-4X6000ADA-Y1 |
| 8x22B | 262GB | 4x NVIDIA A100/H100 80GB | AIME A4004 Server | C32-4XA180-Y1, C32-4XH100-Y1 |
Eine detailliertere Leistungsanalyse verschiedener Hardwarekonfigurationen finden Sie im Abschnitt Mixtral Inferenz GPU Benchmarks dieses Artikels.
Erstellen eines AIME ML Containers
Im Folgenden finden sich die Anweisungen zum Einrichten der Laufzeitumgebung mit dem AIME ML-Container-Management auf dem AIME-Server, der Cloud-Instanz oder der Workstation. Dies könnte natürlich auch mit Conda oder ähnlichen Tools erzielt werden.
Um eine PyTorch 2.3.0-Umgebung für die Installation zu erstellen, verwenden wir den AIME ML-Container, wie in aime-ml-containers beschrieben, mit folgendem Befehl:
> mlc-create mixtral Pytorch 2.3.0 -w=/path/to/your/workspace -d=/destination/of/model/checkpointsDer Parameter -d ist nur notwendig, wenn die Checkpoints nicht im Arbeitsbereich, sondern in einem spezifischen Datenverzeichnis gespeichert werden sollen. Dieser Parameter bindet das Verzeichnis /destination/of/model/checkpoints an /data im Container.
Sobald der Container erstellt ist, öffnet man ihn mit:
> mlc-open mixtralMan arbeitet nun im ML-Container und kann alle erforderlichen Anforderungen sowie notwendige pip- und apt-Pakete installieren, ohne das Host-System zu beeinflussen.
Klonen des Mixtral-Chat-Repositorys
Nun klont man das Mixtral-Chat-Repositorys mit:
[mixtral] user@client:/workspace$
> git clone https://github.com/aime-labs/mixtral_chatund installiert die erforderlichen pip-Pakete im Container mit:
[mixtral] user@client:/workspace$
> pip install -r /workspace/mixtral_chat/requirements.txtMixtral Modell-Checkpoints herunterladen
Die Modellgewichte und der Tokenizer sind kostenlos von den folgenden Quellen herunterladbar:
| Modell | Download-Link |
|---|---|
| 8x7B Instruct | https://models.mistralcdn.com/mixtral-8x7b-v0-1/Mixtral-8x7B-v0.1-Instruct.tar |
| 8x22 Instruct | https://models.mistralcdn.com/mixtral-8x22b-v0-3/mixtral-8x22B-Instruct-v0.3.tar |
| 8x7B | Updated model coming soon! |
| 8x22B | https://models.mistralcdn.com/mixtral-8x22b-v0-3/mixtral-8x22B-v0.3.tar |
Mixtral als interaktiven Chat im Terminal ausführen
Um die Mixtral-Modelle als Chatbot im Terminal auszuprobieren, kann man folgendes PyTorch-Skript verwenden. Die gewünschte Modellgröße sowie die Anzahl der zu verwendenden GPUs lassen sich spezifizieren mit:
[mixtral] user@client:/workspace$
> torchrun --nproc_per_node <num_gpus> /workspace/mixtral_chat/chat.py --ckpt_dir /destination/of/model/checkpoints --tokenizer_path /destination/of/model/checkpoints/tokenizer.modelMixtral Chat als Service mit dem AIME API Server ausführen
AIME API Server einrichten
Informationen zur Einrichtung und zum Starten des AIME API Servers finden sich im Einrichtungsabschnitt der Dokumentation.
Mixtral als API Worker starten
Um das Mixtral-Chat-Modell mit dem AIME-API-Server zu verbinden und bereit zu sein, Chat-Anfragen über die JSON-HTTPS/HTTP-Schnittstelle zu empfangen, fügt man einfach die Flag --api_server gefolgt von der Adresse seines AIME API Servers hinzu:
[mixtral] user@client:/workspace$
> torchrun --nproc_per_node <num_gpus> /workspace/mixtral_chat/chat.py --ckpt_dir /destination/of/model/checkpoints --tokenizer_path /destination/of/model/tokenizer --api_server https://api.aime.info/Der AIME API Server kann auf einfachen Webservice-Webspace-Providern oder innerhalb der Firmen-IT-Struktur gehostet werden. Im obigen Beispiel meldet sich das Modell als Worker für den AIME API Demo-Server an.
Nun fungiert das Mixtral-Modell als Worker-Instanz für den AIME API Server und ist bereit, von den Clients des AIME API Servers beauftragte Anfragen zu verarbeiten.
Für eine Dokumentation, wie man Client-Anfragen an den AIME API Server sendet, lesen Sie bitte hier weiter.
Mixtral Inferenz GPU Benchmarks
Um die Leistung des Mixtral-Workers zu messen, der mit dem AIME API Server verbunden ist, wurde ein Benchmark-Tool entwickelt, das den Server mit der gewünschten Anzahl von Chat-Anfragen simuliert und belastet. Um diese Leistung selber zu messen, installiert man zuerst die benötigten Anforderungen:
user@client:/workspace/aime-api-server/$
> pip install -r requirements_api_benchmark.txtDann startet man das Benchmark-Tool mit:
user@client:/workspace/aime-api-server/$
> python3 run_api_benchmark.py --api_server https://api.aime.info/ --total_requests <number_of_requests> --endpoint_name mixtral_chatrun_api_benchmark.py sendet so viele Anfragen wie möglich parallel und bis zu <number_of_requests> Chat-Anfragen an den API-Server. Jede Anfrage beginnt entweder mit dem initialen Kontext "Tell a long story: Once upon a time" oder einem langen Text, der die volle maximale Kontextlänge ausnutzt. Mixtral erzählt eine Geschichte, bis 500 Token generiert wurden. Die verarbeiteten Token pro Sekunde werden gemessen und über alle verarbeiteten Anfragen gemittelt.
Mixtral 8x7B Inferenz-Performance
Hier wird der Durchsatz in generierten Token pro Sekunde des Mixtral 8x7B- und 8x22B-Modells für verschiedene GPU-Konfigurationen gezeigt. Da die maximale Kontextlänge einen großen Einfluss auf die maximal mögliche Batch-Größe hat, wurden Messungen sowohl mit 32K als auch mit 8K maximaler Kontextlänge durchgeführt.
Auch die initiale Länge des Prompts hat einen Einfluss auf die Leistung, da der Eingabetensor vom Modell verarbeitet werden muss, bevor neue Token generiert werden können. Daher wird die Leistung eines initialen Kontextes, der die volle Kontextlänge ausnutzt, verglichen mit einem viel kürzeren initialen Kontext.
In den Balkendiagrammen wird die maximal mögliche Batch-Größe, die der Anzahl der parallel verarbeitbaren Chat-Sitzungen entspricht, unter dem GPU-Modell angegeben. Die maximal mögliche Batch-Größe steht in direktem Zusammenhang mit der maximalen Kontextlänge und dem verfügbaren GPU-Speicher.
Die Ergebnisse werden als gesamter möglicher Durchsatz in Token pro Sekunde angezeigt. Der kleinere Balken zeigt die Token pro Sekunde für eine einzelne Chatsitzung.
Mixtral 8x7B 32K Kontextlänge GPU Performance
Mit einer Kontextlänge von 32K sind die möglichen maximalen Batch-Größen relativ klein, was zu einer nicht wettbewerbsfähigen Gesamtleistung im Vergleich zu Modellen wie Llama 3 führt. Und die längeren initialen Kontexte verringern die Leistung erheblich.
Durch Reduzierung der maximalen Kontextlänge auf 8K, das Limit von Llama 3, werden viel höhere Batch-Größen erreicht, was zu einer wettbewerbsfähigeren Gesamtleistung führt (siehe den Artikel zu Llama 3 für Llama 3-Benchmark-Ergebnisse).
Mixtral 8x7B 8K Kontextlänge GPU Performance
Mit einer maximalen Kontextlänge von 8K ist es sogar möglich, das 8x7B-Modell auf nur 2x 6000 Ada GPUs auszuführen.
Insbesondere mit den Setups von 2x A100 und 2x H100 liefert Mixtral 8x7B eine bessere Durchsatzrate bei generierten Tokens pro Sekunde, als das Llama 3 70B-Modell.
Mixtral 8x22B Inferenz-Performance von 4x A100 80GB
Das Mixtral 8x22B-Modell hat einen deutlich höheren GPU-Speicherbedarf. Wir haben es bisher nur auf einem Setup mit 4 x A100 80GB getestet. Hier sind die Ergebnisse:
Die menschliche (stille) Lesegeschwindigkeit beträgt etwa 5 bis 8 Wörter pro Sekunde. Mit einem Verhältnis von 0,75 Wörtern pro Token, entspricht dies einer erforderlichen Textgenerationsgeschwindigkeit von etwa 6 bis 11 Tokens pro Sekunde, um als nicht als zu langsam wahrgenommen zu werden.
Eine Echtzeitnutzung des Mixtral 8x22B-Modells auf einem Setup mit 4x A100 80GBGPUs ist möglich, aber wahrscheinlich nur für Anwendungen geeignet, die höchste Textgenauigkeit und nur eine moderate Kontextlänge erfordern.
Fazit
Die Integration von Mixtral mit der AIME API und die einfache Einrichtung bieten Entwicklern eine skalierbare Lösung zur Bereitstellung des Mixtral-Sprachenmodells innerhalb ihrer Softwarelösungen. Durch die Nutzung des Mixtral-Instruct-Mechanismus zusammen mit dem AIME API Server können Entwickler sehr einfach fortschrittliche Anwendungen wie Chatbots, virtuelle Assistenten oder interaktive Kundensupportsysteme entwickeln.
Die Hardwareanforderungen für den Betrieb der Mixtral-Modelle hängen vom Anwendungsfall ab, insbesondere von der gewünschten maximalen Kontextlänge. Es sind verschiedene verteilte GPU-Konfigurationen und erweiterbare Setups möglich, mit denen Tausende von Anfragen verarbeitbar sind. Selbst die minimalen GPU-Anforderungen oder kleinsten empfohlenen AIME-Systeme für jede Modellgröße, mit Einschränkungen für das Mixtral 8x22B-Modell, gewährleisten eine mehr als Echtzeit-Leseleistung für ein nahtloses Multi-User-Chat-Erlebnis.




