
Um die Vorteile einer On-Premise-Lösung zu veranschaulichen, vergleichen wir im Folgenden die Anschaffungs- und Betriebskosten eines auf Deep Learning optimierten AIME 4-GPU Computers mit der Miete eines vergleichbaren cloudbasierten GPU-Servers, der AWS-Instanz p3.8xlarge von Amazon.
Kostenvergleich: Total Cost Of Ownership (TCO)
Um einen direkten Preisvergleich darstellen zu können gehen wir von einem 1-Jahres-Vertrag für die Nutzung einer AWS EC2 P3-Instanz ‚p3.8xlarge‘ in der Region ‚EU(Frankfurt)‘ aus, deren Kosten zu Vertragsbeginn zu 100 % im Voraus beglichen werden (Reserved Instance, All Upfront), den günstigsten Tarif den AWS für einen garantierte Verfügbarkeit anbietet. Um die Berechnung zu vereinfachen, lassen wir weitere Kosten, die für Speicherreservierung und Datendurchsatz bei AWS anfallen würden, außen vor.
Kosten für 1 Jahr
|
|
|
AWS p3.8xlarge |
76.798,04 € |
| AIME R400 4x RTX 2080TI, incl. electricity |
12.051,80 € Sie sparen 84,3% |
| AIME R400 4x Tesla V100, incl. electricity |
41.226,40 € Sie sparen 46,3% |
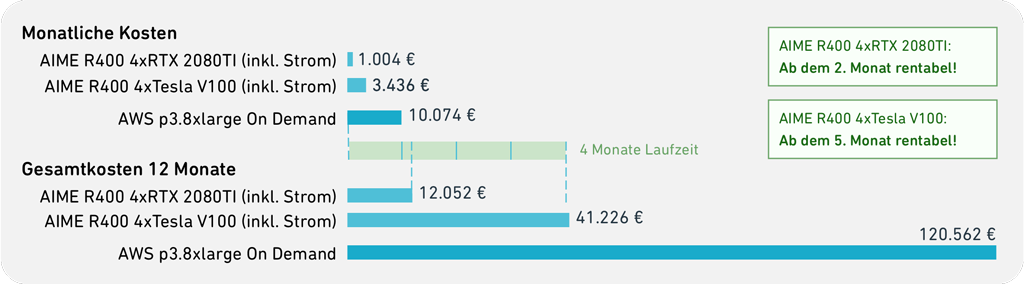
Aus der folgenden Aufstellung des ROI-Charts (Return of Investment) erkennen wir, dass sich AIME Systeme je nach GPU-Bestückung schon ab dem zweiten Monat auszahlen. Hochleistungs-GPUs werden sogar schon ab dem 5. Monat profitabel. Darüber hinaus erhält man im Gegensatz zur AWS-Instanz mit einem On-Premise-Rechner nach vielen Jahren immer noch einen Nutzen aus dem erworbenen System.
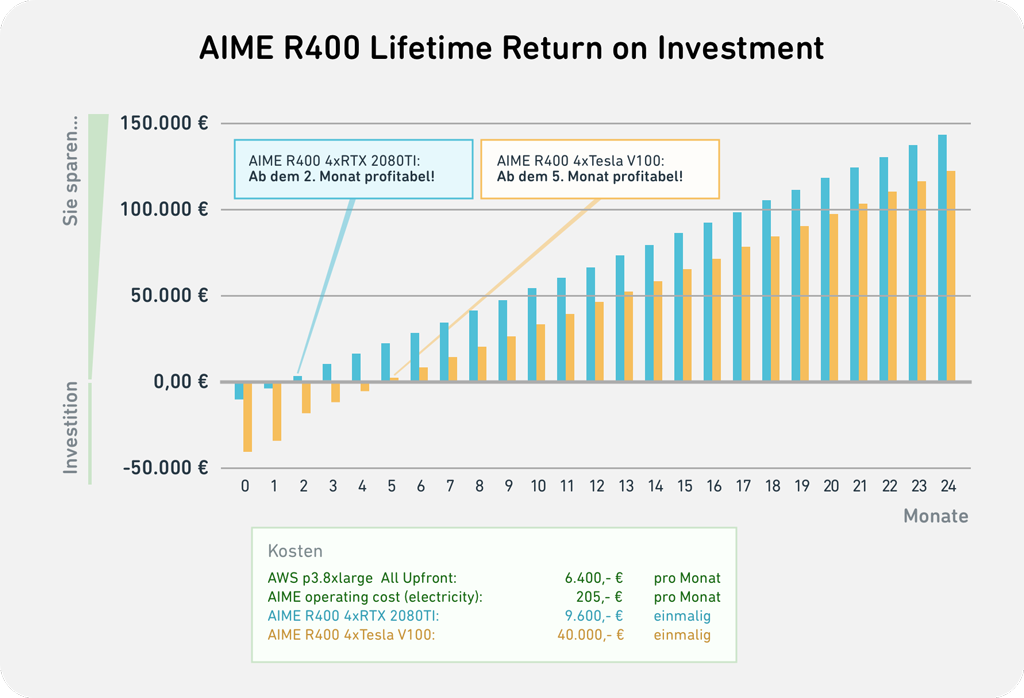
Geld sparen und dabei Leistung hinzugewinnen
Die Gesamtbetriebskosten (TCO) eines AIME R400 Servers beinhalten die Anschaffungskosten des Systems, sowie die Energiekosten. Der Stromverbrauch des R400 Servers wird mit 0,28 € pro kWh bei einem Ökostromanbieter berechnet, wobei wir von einem Verbrauch von 8760 kWh pro Jahr im einjährigen 24/7-Dauerbetrieb unter Vollast ausgehen.
Die Anschaffungskosten eines AIME R400 Servers hängen hauptsächlich von den verbauten GPUs ab. Wir rechnen hier mit zwei Konfigurationen: jeweils vier GPUs des Typs RTX 2080TI bzw. Tesla V100.
Aus der folgenden Abbildung ist ersichtlich, dass man - ohne Leistungseinbußen in Kauf nehmen zu müssen - bei einer Projektdauer von einem Jahr bis zu 108.510,- € an Kosten einspart, wenn man in eine On-Premise-Maschine investiert.
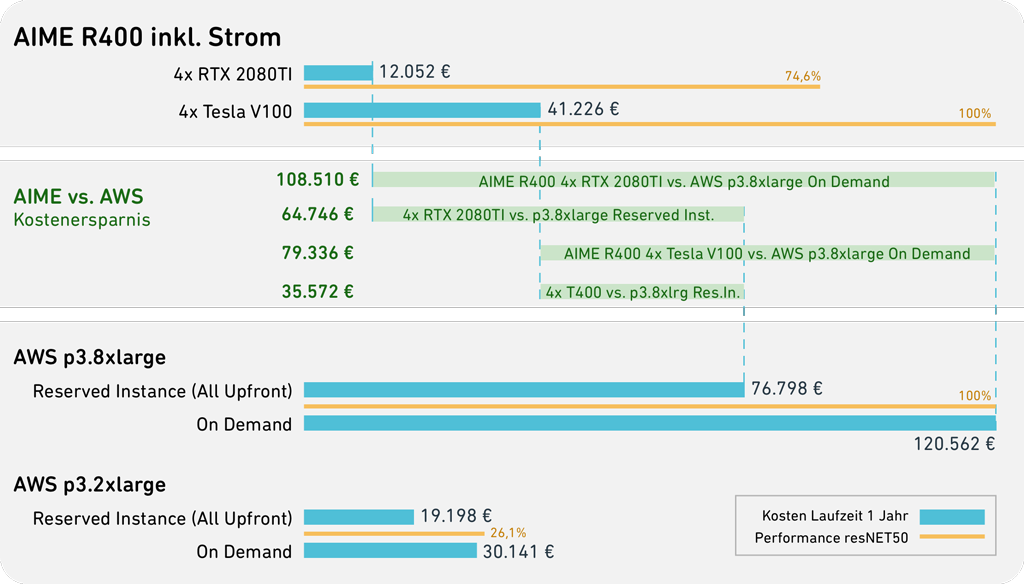
Weitere Vorteile neben den Einsparungen
Im Vergleich zu AWS-Instanzen aus günstigeren Angeboten als der hier zur Berechnung herangezogenen p3.8xlarge erhält man mit einer On-Premise-Lösung ein leistungsstärkeres System für den Bruchteil der Kosten einer Cloud-Lösung.
Betreibt man seine eigene Deep Learning Maschine kommen weitere Vorteile zum Tragen: Man erhält einen schnellere, direkteren Zugriff auf den Datenspeicher, geht keine Kompromisse bei der Datenqualität ein und hat ausreichend Storage mit höheren Transferraten. Zudem bleiben die Unternehmensdaten geschützt, die nicht mehr in die Cloud hochgeladen werden müssen.
Ausgewogen und Vorkonfiguriert
Der AIME R400 wird mit allen gängigen AI Frameworks vorkonfiguriert ausgeliefert, so dass man Out-of-the-Box direkt mit Berechnungen starten kann.
Alle unsere Komponenten wurden aufgrund ihrer Energieeffizienz, Langlebigkeit und hohen Leistungsfähigkeit ausgewählt. Sie sind perfekt aufeinander abgestimmt, sodass es keine Leistungsengpässe gibt. Wir optimieren unsere Hardware im Hinblick auf die Kosten pro Leistung, ohne die Ausdauer und Zuverlässigkeit zu beeinträchtigen.
Unsere Hardware wurde für unsere eigenen Anforderungen an Deep-Learning-Anwendungen entwickelt. Die verbauten Konfigurationen basieren auf jahrelanger Erfahrung mit Deep-Learning-Frameworks und anwendungsspezifischem Bau von PC-Hardware.
Gerne unterbreiten wir Ihnen ein individuelles Angebot mit Ihrer gewünschten Konfiguration.




